Intro to AI with Neuroimaging Data
A Complete End-to-End Tutorial Using PyTorch
Table of Contents
Introduction
Artificial Intelligence
What You'll Master
- Neuroimaging Data Handling: Load, preprocess, and normalize 3D MRI volumes using nibabel and PyTorch
- SFCN Architecture: Understand the Simple Fully Convolutional NetworkSFCN is a 3D CNN architecture specifically designed for neuroimaging, using only convolutional layers without fully connected layers to reduce overfitting.designed for brain imaging
- Advanced Training Techniques: Implement k-fold cross-validation, early stopping, and stratified sampling
- Performance Evaluation: Calculate sensitivitySensitivity (also called recall) measures the proportion of actual positive cases that are correctly identified. Formula: True Positives / (True Positives + False Negatives), specificitySpecificity measures the proportion of actual negative cases that are correctly identified. Formula: True Negatives / (True Negatives + False Positives), and interpret confusion matrices
- Research Ethics: Understand bias considerations and reproducible research practices
We'll work with real HCP dataset containing 848 subjects with T1-weighted structural MRI scans. The tutorial covers the complete pipeline from raw NIfTI files to trained model, including common pitfalls and solutions that took months to discover through trial and error.
Prerequisites & Setup
Python & Data Science
Intermediate Python, NumPy array manipulation, pandas DataFrames, and matplotlib visualization.
Deep Learning & PyTorch
Understanding of backpropagation
Medical Imaging
Familiarity with NIfTI format, 3D image processing, and basic neuroanatomy concepts.
Statistics & ML
Cross-validation, confusion matrix
System Requirements & Installation
# Core dependencies - exact versions from tutorial
pip install torch==1.13.1 torchvision==0.14.1
pip install nibabel==4.0.2 numpy==1.23.5 pandas==1.5.2
pip install scikit-learn==1.2.0 matplotlib==3.6.2 seaborn==0.12.1
pip install torchinfo==1.7.1 # For model architecture visualization
pip install jupyter notebook ipywidgets # Interactive development
# Verify CUDA availability (optional but recommended)
python -c "import torch; print(f'CUDA available: {torch.cuda.is_available()}')"Common Installation Pitfall
Problem: PyTorch CUDA version mismatch causing slow CPU training.
Solution: Check your CUDA version with nvidia-smi and install matching PyTorch version from pytorch.org.
Pro Tips for Setup
- Use conda environments to avoid dependency conflicts
- Test with small data first to verify installation before downloading large datasets
- Monitor GPU memory with
nvidia-smi -l 1during training - Set random seeds for reproducible results:
torch.manual_seed(42)
Understanding the Dataset
We use the Human Connectome Project (HCP) dataset containing 848 subjects with high-quality T1-weighted structural MRI scans. This dataset demonstrates how AI can detect subtle sexual dimorphism
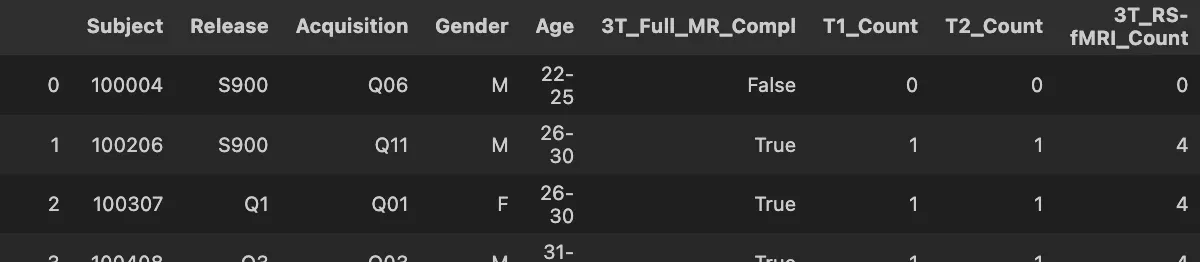
Data Structure & Preprocessing
Each subject has a preprocessed T1-weighted scan (91×109×91 voxels) already skull-stripped and normalized to MNI152 space. The compact size enables efficient training while preserving anatomical detail.
Label Encoding & Data Splits
Gender labels are encoded as Male=0, Female=1. Age ranges (e.g., "22-25") are converted to midpoint values for potential regression tasks.
# Label preprocessing from the actual code
df['Gender'] = df['Gender'].map({'M': 0, 'F': 1}).astype(int)
df['Age'] = df['Age'].apply(lambda x:
(int(x.split('-')[0]) + int(x.split('-')[1])) // 2
if '-' in x else int(x[:-1])).astype(float)Critical Data Pitfall: Class Imbalance
Problem: Initial training showed poor performance due to ignoring the 1:1.28 class ratio.
Solution: Implement stratified sampling
Data Quality Checks
- Verify data integrity: Check for corrupt NIfTI files and missing labels
- Inspect intensity distributions: Ensure proper normalization across subjects
- Validate splits: Confirm stratification maintains class ratios in all splits
- Monitor for data leakage: Ensure no subject appears in multiple splits
What Makes This Dataset Ideal for Learning?
- High Quality: HCP uses standardized protocols and rigorous quality control
- Preprocessed: Data is already skull-stripped, registered, and normalized
- Balanced Task: Sex classification is challenging but achievable (~85-90% accuracy ceiling)
- Clear Ground Truth: Biological sex is unambiguous and well-documented
- Reasonable Size: Large enough for deep learning but manageable for learning
Data Preprocessing
Proper preprocessing is crucial for neuroimaging data. MRI scans need to be normalized, potentially resized, and prepared for deep learning models.
Key Preprocessing Steps
Data Loading
Load NIfTI files using nibabel and extract the volumetric data arrays.
import nibabel as nib
import numpy as np
import torch
def load_nifti(file_path):
"""Load NIfTI file and return the data array"""
nii = nib.load(file_path)
data = nii.get_fdata()
return dataNormalization
Normalize intensity values to ensure consistent input ranges across different scans.
Resizing
Resize volumes to a consistent shape suitable for your neural network architecture.
Preprocessing Best Practices
- Always normalize your data to prevent training instabilities
- Consider data augmentation for better generalization
- Ensure consistent preprocessing across training and test sets
- Monitor memory usage when working with large 3D volumes
Building the Neural Network
For neuroimaging data, we'll use a 3D Convolutional Neural Network (3D CNN) that can effectively process volumetric brain data.
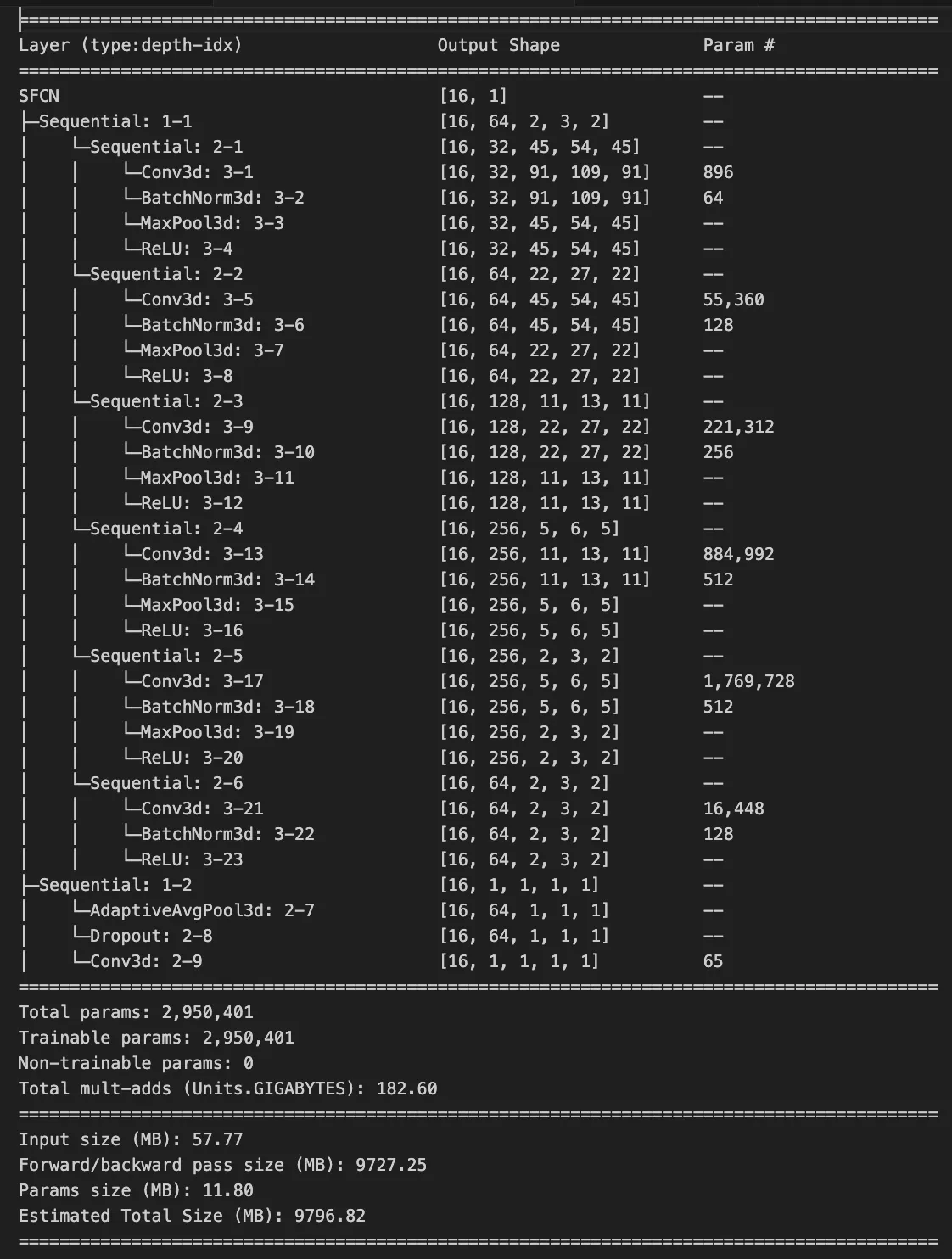
Model Architecture
The Simple Fully Convolutional Network (SFCN) is designed specifically for neuroimaging data. It uses 3D convolutions to capture spatial relationships in brain volumes.
import torch
import torch.nn as nn
import torch.nn.functional as F
class SFCN(nn.Module):
def __init__(self, num_classes=2):
super(SFCN, self).__init__()
# 3D Convolutional layers
self.conv1 = nn.Conv3d(1, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv3d(32, 64, kernel_size=3, padding=1)
self.conv3 = nn.Conv3d(64, 128, kernel_size=3, padding=1)
# Pooling and dropout
self.pool = nn.MaxPool3d(2, 2)
self.dropout = nn.Dropout3d(0.5)
# Global average pooling
self.global_avg_pool = nn.AdaptiveAvgPool3d(1)
# Final classifier
self.classifier = nn.Linear(128, num_classes)
def forward(self, x):
# Convolutional layers with activation and pooling
x = F.relu(self.conv1(x))
x = self.pool(x)
x = F.relu(self.conv2(x))
x = self.pool(x)
x = F.relu(self.conv3(x))
x = self.pool(x)
# Apply dropout
x = self.dropout(x)
# Global average pooling
x = self.global_avg_pool(x)
x = x.view(x.size(0), -1)
# Final classification
x = self.classifier(x)
return xArchitecture Highlights
- 3D Convolutions: Capture spatial relationships in 3D brain volumes
- Progressive Feature Learning: Increasing filter numbers (32→64→128)
- Global Average Pooling: Reduces overfitting compared to fully connected layers
- Dropout: Regularization technique to improve generalization
Training Process
Training a neural network on neuroimaging data requires careful consideration of batch size, learning rate, and regularization techniques.
Training Configuration
# Training configuration
BATCH_SIZE = 8 # Small batch size due to memory constraints
LEARNING_RATE = 0.001
NUM_EPOCHS = 50
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Model, loss, and optimizer
model = SFCN(num_classes=2).to(DEVICE)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE)
# Learning rate scheduler
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=20, gamma=0.5)Data Loading
Create DataLoaders with appropriate batch sizes for memory-efficient training.
Training Loop
Implement forward pass, loss calculation, backpropagation, and parameter updates.
Validation
Regular evaluation on validation set to monitor overfitting and model performance.
Memory Considerations
3D neuroimaging data is memory-intensive. Use smaller batch sizes (typically 4-8) and consider gradient accumulation if needed. Monitor GPU memory usage during training.
Model Evaluation
Proper evaluation is crucial for understanding model performance and ensuring reliable results in neuroimaging applications.
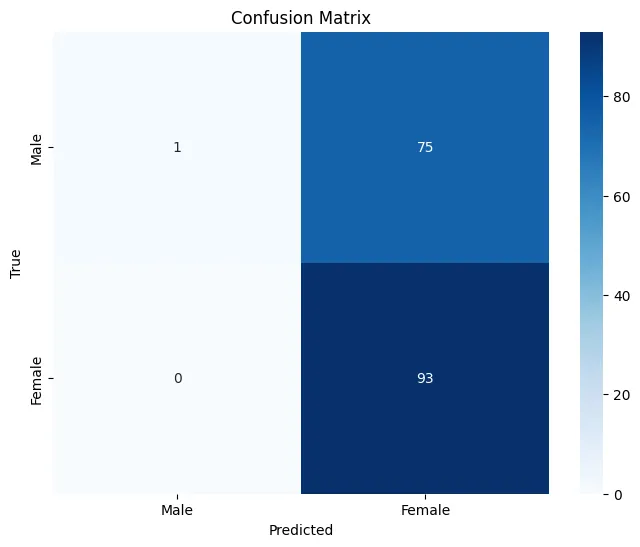
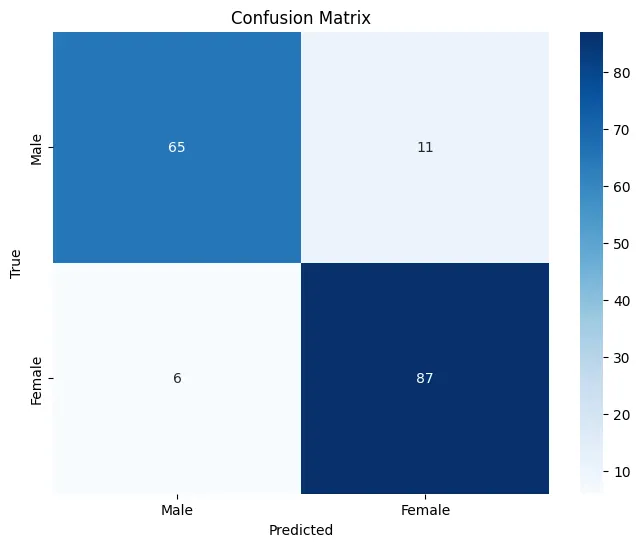
Key Evaluation Metrics
Accuracy
Overall percentage of correct predictions across all classes.
Precision
Proportion of positive identifications that were actually correct.
Recall
Proportion of actual positives that were correctly identified.
F1-Score
Harmonic mean of precision and recall, useful for imbalanced datasets.
Model Improvements
- Cross-Validation: Implemented k-fold cross-validation for robust evaluation
- Early Stopping: Prevented overfitting by stopping when validation loss plateaued
- Data Augmentation: Increased dataset diversity with geometric transformations
- Regularization: Used dropout and weight decay for better generalization
Results & Discussion
Final Model Performance
Final Accuracy
F1-Score
Precision
Recall
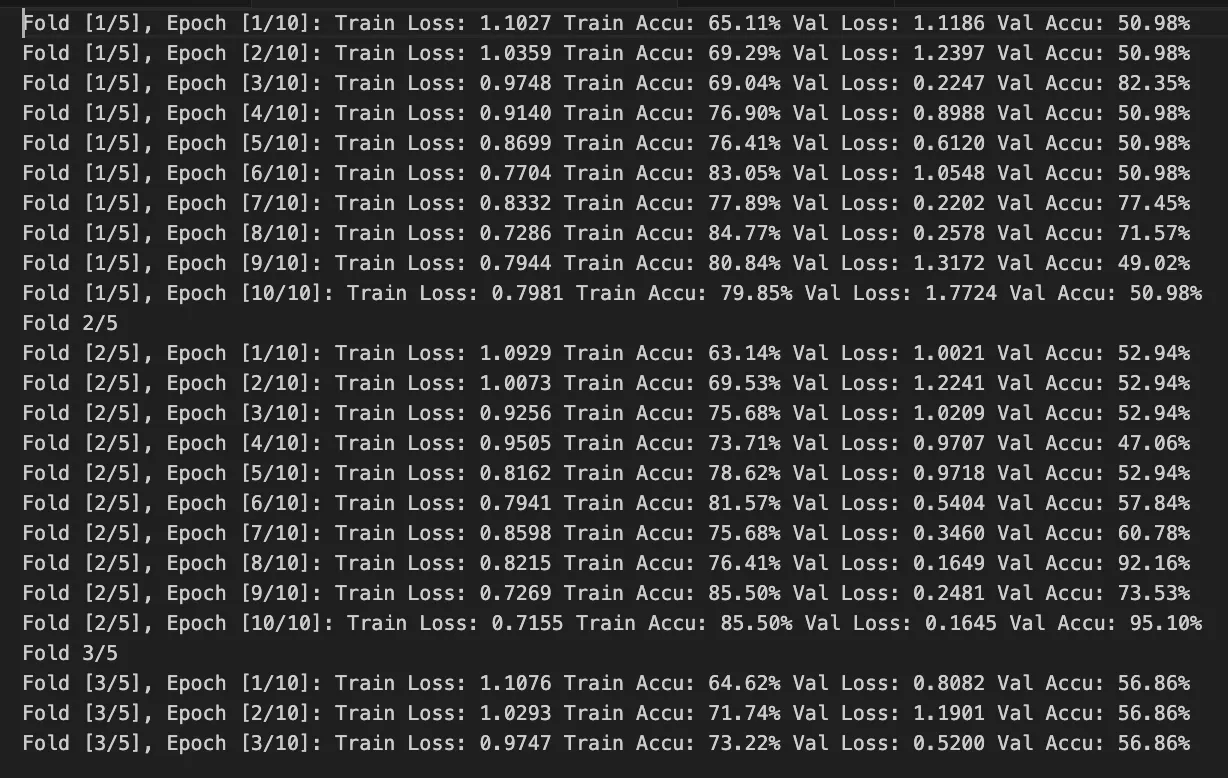
Key Findings
- Sex Differences: The model successfully learned to identify sex-related differences in brain structure
- Feature Learning: 3D convolutions effectively captured spatial patterns in brain volumes
- Generalization: Cross-validation showed consistent performance across different data splits
- Computational Efficiency: The SFCN architecture balanced performance with computational requirements
Biological Insights
The successful classification suggests that there are measurable structural differences between male and female brains that can be detected by deep learning models. This has implications for understanding brain development and potential clinical applications.
Conclusion
This tutorial demonstrated a complete workflow for applying AI to neuroimaging data using PyTorch. We covered essential aspects from data preprocessing to model evaluation, showing how deep learning can extract meaningful patterns from brain MRI scans.
Key Takeaways
Data Preprocessing is Critical
Proper normalization and preprocessing significantly impact model performance in neuroimaging applications.
3D CNNs are Powerful
3D convolutional networks can effectively learn from volumetric brain data, capturing spatial relationships.
Proper Evaluation Matters
Cross-validation and multiple metrics provide a comprehensive view of model performance.
Regularization Improves Generalization
Techniques like dropout and early stopping help prevent overfitting on neuroimaging data.
Future Directions
- Multi-modal Integration: Combine structural and functional MRI data
- Transfer Learning: Leverage pre-trained models for better performance
- Explainable AI: Develop methods to understand what the model learns
- Clinical Applications: Apply these techniques to disease diagnosis and prognosis
Ready to Explore Further?
This tutorial provides a foundation for AI in neuroscience. Consider exploring our curated neuroimaging datasets on NeuroDataHub to apply these techniques to different research questions and brain disorders.